

🚀 En bref : L’intégration d’un agent d’intelligence artificielle dans votre écosystème technique n’est plus un luxe, mais une nécessité stratégique. Cet article détaille les étapes concrètes pour déployer votre premier agent autonome, des fondamentaux architecturaux jusqu’aux pièges à éviter en production. Vous découvrirez comment les modèles de langage deviennent des systèmes décisionnels, comment orchestrer les workflows complexes, et surtout, comment mesurer le succès réel au-delà des démos impressionnantes.
🎯 Comprendre l’architecture fondamentale d’un agent IA : au-delà du simple chatbot
Sommaire de l'article
Pendant mes années de déploiement en environnement critique, j’ai constaté une confusion majeure : beaucoup confondent un chatbot réactif avec un agent autonome véritablement intelligent. Cette distinction est capitale avant toute implémentation.
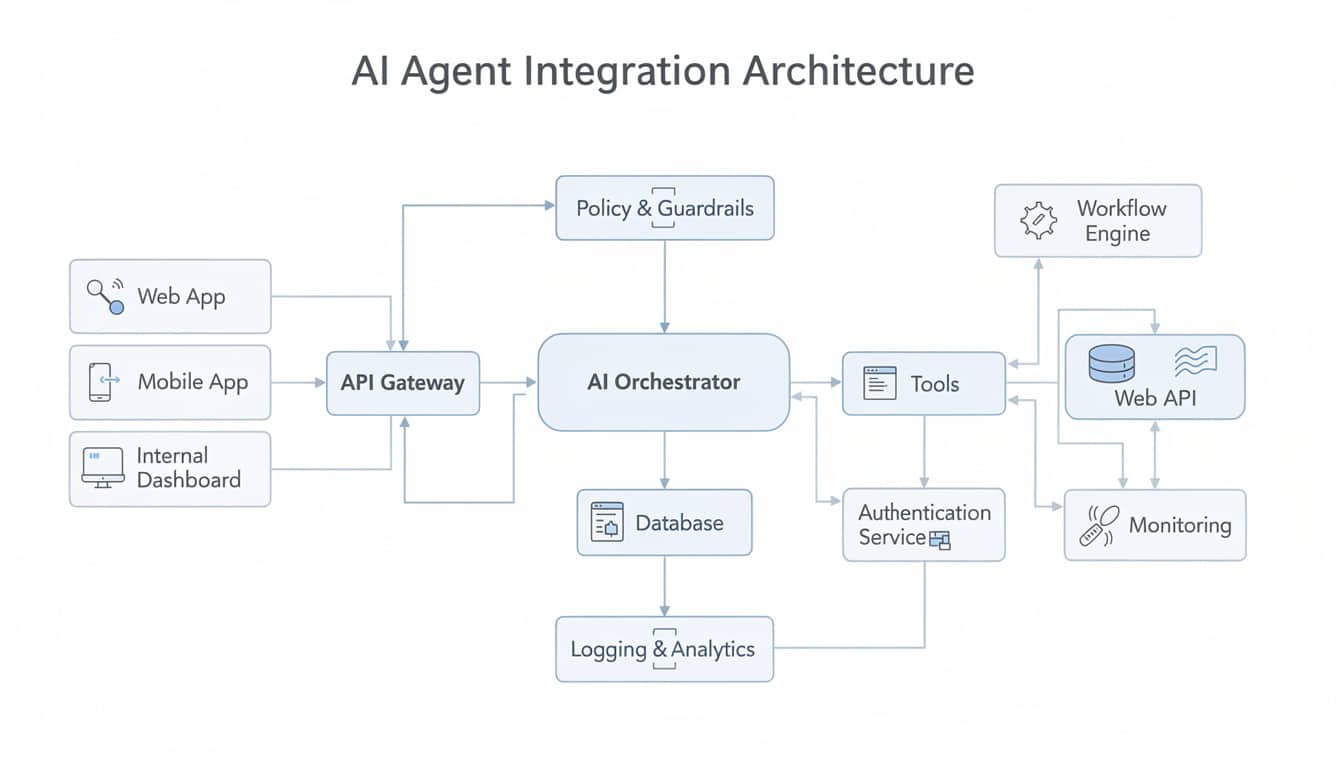
Un agent IA moderne n’est pas simplement un modèle de langage qui répond à des prompts. C’est un système composé de plusieurs couches : un moteur décisionnel (le LLM), une mémoire contextuelle, des outils métier (APIs, bases de données, services externes), et surtout, une capacité de raisonnement itératif. Contrairement à un chatbot linéaire, un agent IA peut planifier une série d’actions, évaluer les résultats, ajuster sa stratégie, puis exécuter les étapes suivantes.
Prenons un exemple concret : vous déployez un agent pour la gestion des demandes clients en finance. Un chatbot basique répondrait « Vous devez appeler le service client ». Un véritable agent va plutôt : interroger la base de données clients, analyser l’historique transactionnel, vérifier les règles de conformité, générer une réponse personnalisée, et proposer des actions correctives automatiques. C’est cette orchestration multietapes qui fait toute la différence.
L’architecture repose également sur un concept clé : la boucle perception-décision-action. L’agent perçoit son environnement (données entrantes), décide de la meilleure action selon son objectif, l’exécute, puis évalue le résultat. Cette boucle se répète jusqu’à la résolution du problème. Lorsque vous déployez votre premier agent, cette architecture doit être pensée dès le départ, car la refactoriser après coup coûte infiniment plus cher.
📌 La clé à retenir : un agent IA n’est pas un chatbot intelligent, c’est une machine de raisonnement autonome capable de planifier et d’exécuter des séquences d’actions complexes.
🛠️ Les briques techniques essentielles : choisir votre stack d’intégration
Vous allez maintenant entrer dans le détail technique. La beauté d’un bon tutoriel d’intégration, c’est de vous montrer comment assembler les pièces, pas de vous submerger avec des centaines de frameworks.
Historiquement, j’ai travaillé avec plusieurs approches. La plus robuste aujourd’hui repose sur trois composants fondamentaux : un LLM (Large Language Model), une base de données vectorielle, et une couche d’orchestration. Voyons chacune.
Le LLM est votre moteur cognitif. Vous pouvez utiliser des APIs propriétaires comme OpenAI ou une stack open-source comme Llama. Le choix dépend de vos contraintes : latence acceptable, coûts, sensibilité aux données, infrastructure disponible. Pour un premier déploiement, je recommande une approche hybride : commencez avec une API managée pour la rapidité, puis migrez progressivement vers un modèle open-source si vous avez des volumes critiques.
La base de données vectorielle est votre mémoire. Pourquoi vectorielle ? Parce que les vecteurs (représentations numériques) permettent au modèle de chercher des informations par similarité sémantique, pas par mots-clés. Vous stockez les documents, les politiques métier, les historiques de cas résolus sous forme vectorisée. Quand votre agent doit répondre, il cherche les vecteurs les plus proches, ce qui est infiniment plus pertinent qu’une recherche textuelle basique. Elasticsearch, Pinecone, ou Weaviate sont vos meilleurs alliés ici.
La couche d’orchestration est votre chef d’orchestre. C’est elle qui décide quels outils utiliser, dans quel ordre, avec quels paramètres. Des frameworks comme AutoGPT ou BabyAGI ont montré les premières approches, mais en 2026, des solutions plus matures comme LangChain, ou des alternatives specifiées pour les agents autonomes, constituent l’arsenal de production.
📌 Point crucial : ne cherchez pas la solution « parfaite ». Chaque stack a des compromis. Une solution cloud managée offre la rapidité, un modèle open-source offre le contrôle. À vous de choisir selon votre contexte métier.
📋 Les étapes concrètes de déploiement : du prototype à la production
Passons au tutoriel pratique. Je vais vous décrire le processus que j’applique systématiquement chez mes clients, du concept à la mise en production. Cela évite 80% des déboires que j’observe.
Étape 1 : Définir le périmètre et les objectifs mesurables
Avant d’écrire une seule ligne de code, articlez précisément : Qu’est-ce que cet agent va faire ? Quels sont les critères de succès ? Ne dites pas « automatiser le support client » (trop flou), dites « réduire le temps de résolution des demandes de réinitialisation de mot de passe de 15 minutes à 2 minutes, avec un taux de satisfaction client supérieur à 90% ».
Je travaille souvent avec une matrice simple : impact métier vs complexité technique. Privilégiez les cas d’usage haute valeur, faible complexité pour débuter. Une demande bancaire automatisée rapporte plus qu’une analyse de sentiments sur les réseaux sociaux, et c’est souvent plus simple à instrumenter.
Étape 2 : Construire le socle de données
Votre agent est aussi intelligent que vos données. Si vous voulez qu’il comprenne vos politiques métier, vos FAQ, vos précédents cas résolus, il faut les ingérer proprement. Cela signifie : nettoyage des documents, segmentation intelligente (chunking), génération des vecteurs d’embedding, et stockage dans votre base vectorielle.
Cette étape prend souvent 30-40% du projet. Les gens la sous-estiment systématiquement. Investissez du temps ici, les résultats seront exponentiellement meilleurs. Une FAQ bien segmentée et bien vectorisée vaut mille prompts mal écrits.
Étape 3 : Définir les outils accessibles à l’agent
Un agent sans outils est impuissant. Il doit pouvoir : interroger votre CRM, lancer des appels API, vérifier une base client, valider une conformité réglementaire. Vous allez mapper chaque action possible à un outil. Exposez ces outils via des descriptions claires que le modèle comprendrait facilement.
Exemple simplifié : au lieu de dire « Fonction qui récupère les données client », dites : « Outil de recherche client : prend en entrée un email ou un ID client, retourne le nom, l’adresse, l’historique d’achat et le statut de conformité. Utilise cet outil quand tu dois vérifier les informations d’une personne avant de traiter sa demande ».
Étape 4 : Implémenter la boucle d’inférence
C’est où le « tutoriel d’intégration » devient vraiment concret. Vous écrivez la boucle qui sera exécutée des milliers de fois. Pour chaque requête utilisateur : l’agent lit le contexte, décide les outils à utiliser, les exécute, analyse les résultats, décide l’action suivante, jusqu’à résolution ou escalade.
Cette boucle doit être robuste : gestion des timeout, retry logic sur les appels externes, détection des boucles infinies, fallback gracieux sur erreur. En production, une agent qui plante silencieusement est pire qu’un agent qui n’existe pas.
Étape 5 : Instrumentation et monitoring
Vous mettez en place la télémétrie : chaque décision de l’agent est loguée, tracée, analysée. Quel outil a été appelé ? Combien de temps ? Quel résultat ? Quelle action a suivi ? Ces données sont vos or : elles vous permettront d’améliorer le comportement en continu.
📌 Un secret rarement partagé : le déploiement n’est pas la fin, c’est le début. Les 6 premiers mois en production déterminent si votre agent devient une success story ou un coûteux ornement.
🔍 Les pièges courants et comment les éviter : leçons apprises sur le terrain
Mes années de déploiement m’ont confronté à un catalogue impressionnant d’erreurs. Voici les plus coûteuses, et comment les éviter.
Piège 1 : Confier trop rapidement des décisions critiques à l’agent
Vous venez de déployer votre premier agent IA, il marche bien sur les tests. Alors, tentant, de lui donner directement le pouvoir d’approuver des virements bancaires, ou de résilier des contrats clients. Grosse erreur. Les LLM hallucinent, c’est-à-dire qu’ils inventent des réponses avec une confiance déconcertante. Commencez par des tâches de lecture et de proposition, pas de décision finale.
Sur mes déploiements en FinTech, nous avons strictement respecté une hiérarchie : proposition automatique → validation humaine → exécution. Cela réduit les risques de 95% tout en conservant 80% de l’automatisation.
Piège 2 : Ignorer la dérive du modèle en production
Un agent formé sur des données de janvier 2025 va progressivement diverger de la réalité métier en août 2025. Les règles changent, les cas d’usage évoluent, les données deviennent obsolètes. Vous devez prévoir une stratégie de ré-entraînement ou de fine-tuning régulier.
Je recommande une révision mensuelle des performances, avec un seuil d’alerte si le taux d’erreur dépasse 5%. Quand c’est le cas, vous rechargez vos données, vous re-vectorisez, vous testez en sandbox avant de repousser.
Piège 3 : Sous-estimer les coûts de latence et d’API
Un appel au LLM coûte. Deux appels : c’est le double. Dix appels pour résoudre une simple demande, c’est trop cher, trop lent, et frustrante pour l’utilisateur. Vous devez optimiser le nombre d’appels par résolution.
Technique : utilisez le prompt chaining (enchaîner plusieurs instructions dans un seul appel au lieu de plusieurs appels) et l’in-context learning (fournir des exemples de réponses attendues dans le prompt lui-même).
Piège 4 : Négliger la transparence et l’explicabilité
Vos utilisateurs (ou auditeurs) vont poser la question : « Pourquoi l’agent a-t-il pris cette décision ? » Si vous ne pouvez pas répondre, vous avez un problème de conformité, d’éthique, et de confiance utilisateur. Votre agent doit pouvoir tracer chaque étape de son raisonnement.
En santé, en finance, en juridique, c’est non-négociable. Même dans un contexte moins régulé, c’est une question de crédibilité. Un agent qui dit « j’ai approuvé votre demande car … » inspire plus confiance qu’un agent qui disparaît dans une boîte noire.
📌 Le facteur différenciant : les meilleures implémentations d’agents IA ne sont pas celles avec les modèles les plus avancés, mais celles avec les meilleures boucles de feedback et d’amélioration continue.
🚀 Orchestration avancée et escalabilité : passer au niveau supérieur
Maintenant que vous avez un agent fonctionnel, comment passer à l’étape suivante ? Comment gérer plusieurs agents, des workflows parallèles, et une charge croissante ?
Multi-agents et collaboration
Un seul agent a des limites. Imaginez un workflow de résolution de demande client complexe : une première agent analyse la demande, une deuxième consulte la base client, une troisième valide la conformité, une quatrième générer la réponse. Chaque agent se spécialise dans son domaine.
Pour orchestrer ces agents, vous avez besoin d’un contrôleur central qui décide quel agent appeler, quand, et comment fusionner les résultats. C’est exactement ce que résout l’approche des agents autonomes. Chaque agent est responsable de sa tâche, le système global bénéficie de la parallélisation et de la spécialisation.
Gestion des états et mémoire distribuée
Quand vous avez 10 agents en parallèle, gérer une conversation cohérente devient complexe. L’état doit être partagé, synchronisé, et tolérant aux pannes. Redis ou une base de données distribuée devient essentiellement pour maintenir la cohérence.
Je recommande une architecture où chaque agent a sa propre mémoire court-terme (contexte de la conversation en cours) et accède à une mémoire partagée long-terme (historique, règles, données métier). Cela évite les conflits tout en assurant la continuité.
Scaling horizontal et conteneurisation
Un agent IA en production n’existe pas seul. Il existe en cluster : plusieurs instances derrière un load balancer, prêtes à gérer les pics de charge. Docker et Kubernetes deviennent vos alliés. Chaque agent est un conteneur que vous déployez, scalez, versionnez indépendamment.
En production, j’utilise une stratégie simple : déployer chaque agent comme un microservice REST, les exposer derrière une gateway API, instrumenter chacun avec des métriques Prometheus, et alarmer sur les seuils clés.
Amélioration continue via le feedback utilisateur
Votre agent résout une demande. L’utilisateur évalue la réponse : « Utile » ou « Inutile ». Ces signaux simples deviennent votre engine de progression. Vous collectez ces feedbacks, les analysez, identifiez les patterns d’erreurs, et mettez à jour votre knowledge base ou vos prompts.
Cela crée une boucle d’amélioration autonome : plus l’agent sert d’utilisateurs, meilleure est sa performance. Cet effet de réseau est un multiplicateur d’impact parfois négligé par les implémentateurs.
📌 Clé stratégique : l’agent autonome n’atteint son plein potentiel que s’il peut apprendre de son utilisation réelle et s’adapter en continu.
🎓 Ressources et prochaines étapes : où aller pour approfondir votre compétence
Vous avez terminé ce tutoriel d’intégration. C’est un bon début, mais l’apprentissage ne s’arrête pas ici. L’IA évolue vite, et votre compétence doit suivre.
Pour solidifier vos fondamentaux
Comprendre en profondeur comment les agents IA résolvent des problèmes concrets nécessite d’explorer des cas d’usage réels. Le comparatif des outils agentiques offre une vision pragmatique de ce qui existe sur le marché et comment les choisir selon votre contexte. C’est crucial avant de verrouiller votre architecture.
Pour déboguer les problèmes spécifiques
Vous allez rencontrer des défaillances propres à votre contexte. Un agent qui donne de mauvaises réponses en santé, ou qui divague en finance, c’est souvent un problème de données, de prompts, ou de cadrage du problème. Comprendre pourquoi une IA donne des réponses erronées vous aidera à diagnostiquer et corriger ces problèmes avant qu’ils affectent vos utilisateurs.
Pour explorer les tendances émergentes
L’IA en finance, en santé, en entreprise évoluent différemment selon les secteurs. Les cas d’usage en finance et l’évolution des assistants personnels comme Siri offrent des perspectives sur où va l’industrie. Ces insights vous aideront à anticiper les besoins futurs de vos propres déploiements.
Pour maîtriser les subtilités du comportement d’apprentissage
Au-delà de l’intégration basique, explorer comment les modèles comprennent les patterns subtils enrichira votre intuition sur les limites et possibilités des systèmes IA. Cela vous évitera les faux espoirs et les investissements mal placés.
Communauté et pratique continue
Rejoignez des groupes d’ingénieurs IA, lisez les papers récents (arXiv, ResearchGate), participez à des hackathons. La courbe d’apprentissage en IA est pentue, et la pratique régulière est votre meilleur allié.
Enfin, testez systématiquement. Chaque nouveau modèle (GPT-5, Llama 4, etc.) mérite un POC (Proof of Concept) rapide pour évaluer son impact sur vos cas d’usage. Ne restez pas bloqué sur votre première décision technique.
🎯 Le message final : intégrer un agent IA n’est pas une décision technique à court terme, c’est une investissement stratégique dans la capacité opérationnelle long-terme de votre organisation. Faites-le bien, mesurez, iterez, et vous ouvrirez des portes que vous n’aviez pas anticipées.
Author Profile
-
🚀 Expert en systèmes autonomes et architectures d'Agents IA
Passionné par l'ingénierie logicielle depuis plus de 12 ans, j'ai fait de l'intégration de solutions cognitives mon terrain de jeu privilégié. Observateur attentif de la révolution technologique actuelle, je consacre aujourd'hui mon expertise à accompagner les entreprises dans une transition cruciale : passer du "Chatbot passif" à l'Agent autonome, capable de raisonner et d'exécuter des tâches complexes en toute indépendance.
🎓 Mon Parcours & Certifications
Mon approche repose sur un socle académique solide et une mise à jour constante de mes compétences :
- Ingénieur en Informatique : Diplômé avec une spécialisation en Intelligence Artificielle, j'ai acquis les bases théoriques indispensables à la compréhension des réseaux de neurones.
- Certifications Spécialisées : Certifié en Deep Learning (DeepLearning.AI) et en Architecture Cloud (AWS), je maîtrise les infrastructures nécessaires au déploiement de l'IA à grande échelle.
- Formation Continue : Je mène une veille active et technique sur les frameworks qui redéfinissent notre métier, tels que LangChain, AutoGPT et CrewAI.
🛠 Expérience de Terrain
Avant de me lancer dans l'aventure Agentlink.org, j'ai piloté le déploiement de modèles de langage (LLM) pour des acteurs exigeants de la FinTech et de la Supply Chain. Mon expertise ne s'arrête pas au code (Python, bases de données vectorielles) ; elle englobe une vision stratégique pour transformer ces innovations en leviers de croissance concrets pour les métiers.
Latest entries
 Comparatif Agents IA - Outils - Logiciels29 juin 2026Benchmarking des performances de raisonnement entre les principaux orchestrateurs du marché
Comparatif Agents IA - Outils - Logiciels29 juin 2026Benchmarking des performances de raisonnement entre les principaux orchestrateurs du marché Comprendre Agents IA - Cas d'usages28 juin 2026J’ai laissé un agent autonome gérer mon service client pendant un mois
Comprendre Agents IA - Cas d'usages28 juin 2026J’ai laissé un agent autonome gérer mon service client pendant un mois Comparatif Agents IA - Outils - Logiciels25 juin 2026Stratégie de déploiement : intégrer Microsoft AutoGen dans un écosystème d’entreprise complexe
Comparatif Agents IA - Outils - Logiciels25 juin 2026Stratégie de déploiement : intégrer Microsoft AutoGen dans un écosystème d’entreprise complexe Comprendre Agents IA - Cas d'usages25 juin 2026Ce que les développeurs ne vous disent pas sur la création d’assistants IA
Comprendre Agents IA - Cas d'usages25 juin 2026Ce que les développeurs ne vous disent pas sur la création d’assistants IA







